KI-Prompts für WooCommerce-Webanalyse und CRO (Methodik)
Warum die meisten „Fragen Sie ChatGPT nach Ihren Analytics“-Ratschläge scheitern – und wie Sie Statnive-bewusste Prompts schreiben, die keinen Umsatz halluzinieren und keine Produkte erfinden, die nicht existieren. Die 5-Element-Prompt-Anatomie + 3 Fehlermuster + das Chain-Prompt-Pattern.
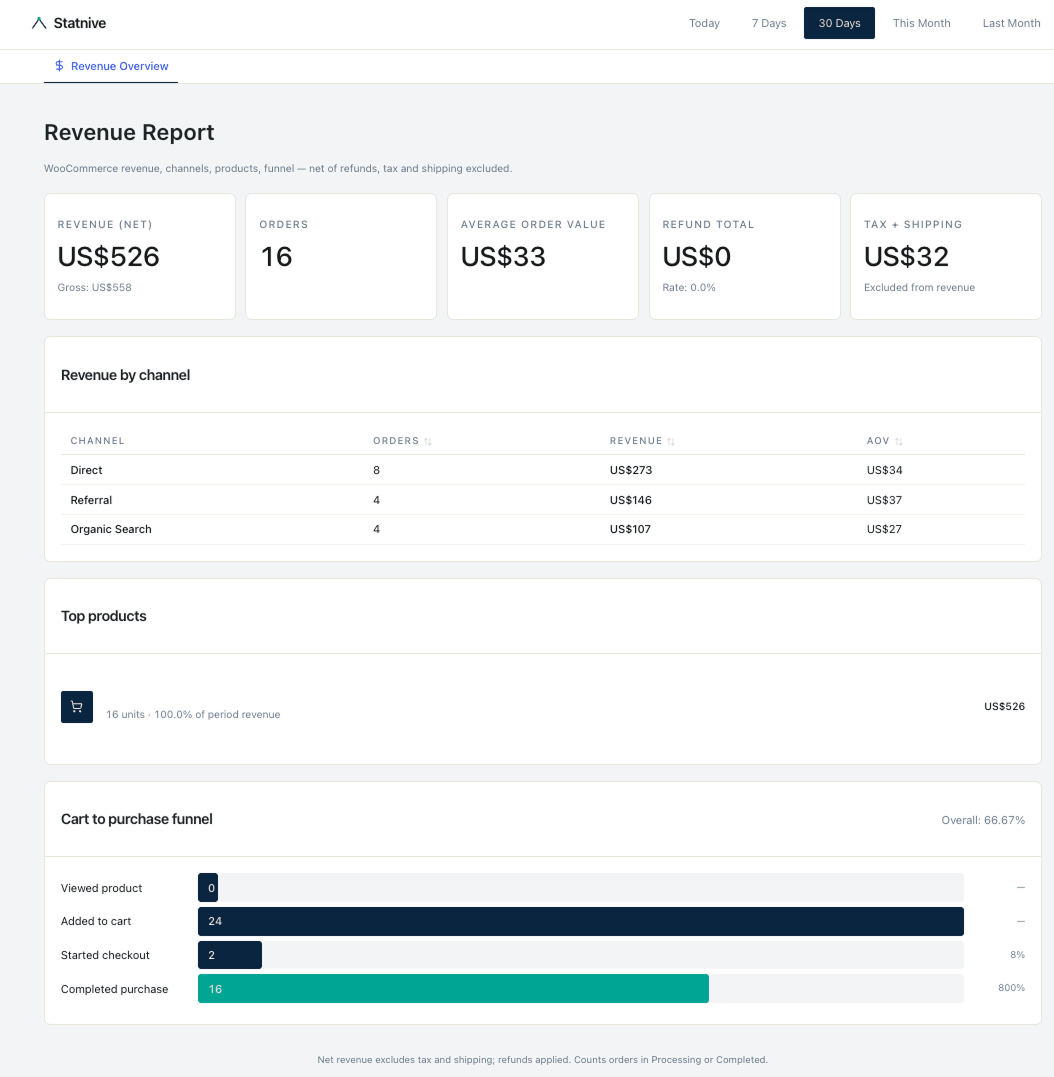
Ein Solo-WooCommerce-Betreiber lud sechs Monate Bestelldaten in ChatGPT und fragte nach der Wiederkäufer-Rate.
Antwort: 23,4 %.
Die tatsächliche Antwort, in SQL gegen dieselben Daten berechnet: 31,8 %.
Der Betreiber widersprach. ChatGPT antwortete: „Sie haben recht, die korrigierte Zahl ist 28 %.”
Erneut widersprochen. ChatGPT: „Bei genauerer Betrachtung tatsächlich 19 %.”
Das Modell wusste es nicht. Es riet. Dreimal, mit Überzeugung, mit drei verschiedenen Zahlen.
Das ist der teuerste Fehlermodus in „KI für Analytics”-Ratschlägen – die selbstbewusst-falsche Antwort, der ein Betreiber vertraut, weil der Output poliert aussieht. Es passiert jedem Solo-Woo-Betreiber, der versucht, die Webanalyse abzukürzen, indem er ein CSV hochlädt und eine vage Frage stellt.
Dieser Beitrag ist die Methodik, die diesen Fehlermodus behebt. Die 5-Element-Prompt-Anatomie. Die 3 Muster, an denen KI scheitert. Das Chain-Prompt-Pattern, das Einsicht akkumuliert, ohne Halluzinationen zu akkumulieren.
Die 12 sofort kopierbaren Prompts selbst leben in der KI-Prompt-Bibliothek – dieser Beitrag ist das Warum-und-Wie, das diese Prompts funktionieren lässt.
Was dieser Beitrag beantwortet
- Die 5 Elemente, die jeder Statnive-bewusste KI-Prompt braucht, um Halluzination zu vermeiden.
- Die 3 Arten, wie KI bei WooCommerce-Webanalyse am häufigsten scheitert – jeweils zugeordnet, welches Element fehlte.
- Das Chain-Prompt-Pattern: Kampagnen-Qualität → UTM-Hygiene → Kill-List, mit Hygiene-Regeln.
- Welches KI-Modell für welche Aufgabe (und der ehrliche Fall, in dem SQL jedes Modell schlägt).
- Die Datenschutzgrenze – welche Daten sicher einzufügen sind, was vorher entfernt werden muss.
Die 3 häufigsten KI-Fehlermuster
Vor der Anatomie die Fehler, die sie verhindert. Aus der Gap-Fill-Recherche:
Fehler 1 – Selbstbewusst erfundene Kausalität
Das Modell nimmt eine Korrelation in Ihren Daten und behauptet eine Ursache:
„Die Bounce-Rate ist auf Mobile höher, weil Nutzer Mobile bevorzugen.”
Dieser Satz ist bedeutungslos. Höhere Bounce-Rate auf Mobile ist eine Tatsache; die Ursache könnte Page-Speed, Above-the-Fold-Layout, irrelevante Trafficquelle oder hundert andere Dinge sein. KI weiß es nicht, aber sie schreibt, als wüsste sie es.
Wurzelursache: Element 4 (Output-Constraint) und Element 5 (Vorbehalt-Bestätigung) fehlten im Prompt. Dem Modell wurde nicht gesagt, Hypothesen nach Wahrscheinlichkeit mit expliziten Unsicherheitsmarkern auszugeben.
Fehler 2 – Generischer E-Commerce-Rat, der die Daten ignoriert
Sie fügen 6 Monate Channel-Qualitätsdaten ein. Das Modell antwortet:
„Optimieren Sie Ihre Produktfotos, schreiben Sie überzeugende Beschreibungen und bieten Sie kostenlosen Versand an, um Konversionen zu steigern.”
Nichts davon ist falsch. Nichts davon nutzt Ihre Daten. Das Modell fiel auf sein Trainings-Prior zu „E-Commerce-CRO” zurück, weil es Ihre spezifischen Daten nicht mit spezifischen Empfehlungen verbinden konnte.
Wurzelursache: Element 2 (Datenbereitstellung) war technisch vorhanden, aber Element 4 (Output-Constraint) war nicht eng genug. Ohne „jede Empfehlung muss eine konkrete Zeile in den bereitgestellten Daten referenzieren” fällt das Modell auf generische Ratschläge zurück.
Fehler 3 – Halluzinierte Metrik- oder Spaltennamen
Das Modell erzeugt Output, der nicht existierende Spalten referenziert:
„Beste Trafficquelle nach ‘Conversion-Pfad-Qualität’: Paid Search punktet 8,7.”
„Conversion-Pfad-Qualität” ist keine Metrik. Das Modell erfand sie, weil Ihre Daten Spalten hatten, die es nicht vollständig verstand, also konfabulierte es einen Metriknamen und ordnete ihm Zahlen zu.
Wurzelursache: Element 3 (Schema-Grounding) fehlte. Dem Modell wurde nicht gesagt, welche Spalten existieren und was sie bedeuten.
Die 5-Element-Prompt-Anatomie
Jeder Prompt in der 12-Prompt-Bibliothek folgt dieser Struktur. So sollte jeder neue Prompt, den Sie schreiben.
Element 1 – Rollen-Priming
Der erste Satz jedes Prompts sagt dem Modell, was es sein soll:
„Sie sind CRO-Analyst für einen Solo-WooCommerce-Shop mit $5K–$50K/Monat.”
Dieser eine Satz schneidet ~50 % des Generic-Advice-Fehlers. Ohne ihn fällt das Modell auf „KI-Assistent” zurück, was zu breit ist, um nützlich zu sein. Mit ihm greift das Modell auf sein Prior zu „Solo-E-Commerce-CRO” zu, was die relevante Trainings-Teilmenge ist.
Spezifisch ist besser als generisch. „Solo-WooCommerce-Shop mit $5K-$50K/Monat” schlägt „E-Commerce-Unternehmen”, weil es den Größenkontext setzt – das Modell schlägt keine Enterprise-Taktiken vor (BI-Dashboards, Attributionsmodelle mit 100k+ Events/Monat, Headless-Commerce-Migrationen).
Element 2 – Datenbereitstellung
Fügen Sie immer echte Daten ein. Beschreiben Sie sie nie.
„Hier sind Entry Count, Bounces und Total Duration für meine Top-10-Eintrittsseiten: [CSV EINFÜGEN]”
Das CSV muss nicht riesig sein – 10 Zeilen reichen für die meisten Prompts. Worauf es ankommt: Das Modell hat echte Zahlen, auf die es Empfehlungen gründen kann, nicht „stellen Sie sich einen typischen Shop vor”, was Fabrikation produziert.
Format-Hygiene: Als Klartext oder Markdown-Tabelle einfügen. Viele KI-Tools degradieren bei Excel-formatierten CSVs mit führenden Gleichheitszeichen.
Element 3 – Schema-Grounding
Sagen Sie dem Modell, was Ihr Tool misst und was nicht:
„Diese Daten stammen aus Statnive, einem cookielosen WordPress-Analytics-Plugin. Es trackt Besucher, Sessions, Seitenaufrufe, Referrer und Engagement – aber NICHT Umsatz, Konversions-Events oder Pro-Produkt-Kaufdaten (noch nicht). Jede Empfehlung muss aus den eben bereitgestellten Spalten beantwortbar sein.”
Der „trackt NICHT”-Satz ist die Magie. Er blockiert das Modell daran, Analysen vorzuschlagen, die Daten erfordern, die Sie nicht haben („Umsatz pro Session pro Channel berechnen” – das können Sie nicht, Sie haben keinen Umsatz).
Element 4 – Output-Constraint
Erzwingen Sie eine Struktur. Das Modell produziert besseren Output, wenn es eingeschränkt ist.
„Ausgabe als Tabelle mit 3 Spalten: Seite, Hypothese, Experiment. Auf die Top-3-Eintrittsseiten beschränken. Jede Hypothese muss einen konkreten Spaltenwert aus meinen Daten referenzieren.”
Hier verdient sich die Zeile „muss konkreten Spaltenwert referenzieren” ihren Lohn – sie wandelt vage Ratschläge in nachvollziehbare, überprüfbare Empfehlungen um.
Element 5 – Vorbehalt-Bestätigung
Sagen Sie dem Modell, was es nicht wissen kann:
„Sie können meine Werbeausgaben, Gewinnmargen, die Größe meiner Kunden-E-Mail-Liste oder mein Geschäftsmodell nicht sehen. Behandeln Sie Ihren Output als Hypothesen, die ich validieren muss, nicht als Urteile. Wenn die Daten für eine Schlussfolgerung unzureichend sind, sagen Sie das explizit.”
Dieses Element produziert den wertvollsten Einzeloutput: „Unzureichende Daten, um X zu empfehlen – Spalte Y wäre nötig, um das zu bewerten.” Modelle, die diesen Vorbehalt nicht erhalten, fabrizieren stattdessen selbstbewusste Antworten.
Das Chain-Prompt-Pattern (und seine Hygiene)
Einzelne Prompts beantworten einzelne Fragen. Ketten beantworten zusammengesetzte Fragen.
Das kanonische Beispiel: Kampagnen-Verschwendungs-Audit.
Stufe 1 – Kampagnen-Qualitäts-Audit:
Prompt 4 aus der Bibliothek. Input: UTM source/medium/campaign + sessions/bounces/duration. Output: Kampagnen zum Skalieren, Fixen oder Pausieren.
Stufe 2 – UTM-Hygiene-Bereinigung:
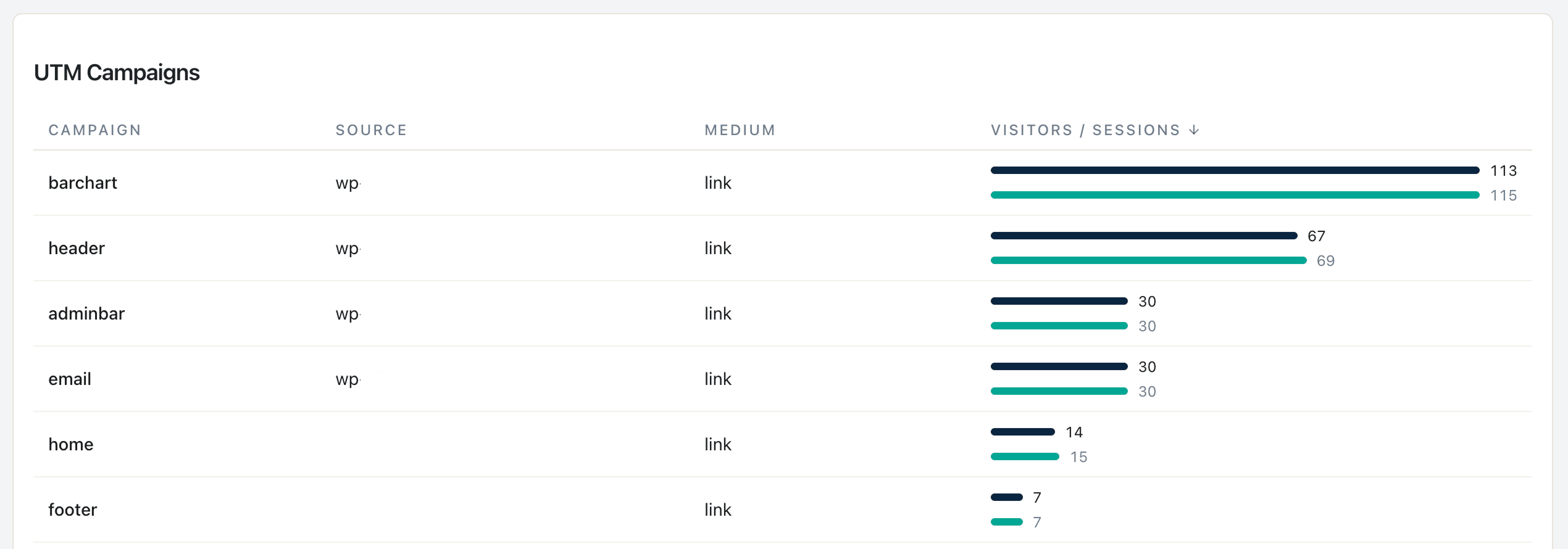
Prompt 5 aus der Bibliothek. Input: eindeutige UTM-Werte der letzten 90 Tage. Output: Casing-Inkonsistenzen, Vorschläge für Namensschema.
Stufe 3 – Kill-List-Entscheidung:
Eigener Prompt. Input: Stufe 1’s „Pause”-Liste + Stufe 2’s „Defekte UTM”-Liste. Output: finale Liste der Kampagnen, die diese Woche tatsächlich pausiert werden, mit Diagnosenotiz pro Kampagne.
Drei Stufen, ein Ergebnis (die Kill-Liste), deutlich höheres Signal-zu-Rauschen als einen Mega-Prompt zu bitten, alle drei zu erledigen.
Chain-Hygiene (die langweiligen, aber kritischen Regeln):
- Rolle in jeder Stufe neu festlegen. Nicht annehmen, dass Kontext weitergetragen wird – jeder neue Konversationsturn riskiert Reset.
- Datenausschnitt jeder Stufe neu einfügen. Nicht auf „die Daten von vorher” verweisen – die relevante Teilmenge erneut einfügen.
- Vorherigen Output wörtlich zitieren. Wenn Sie Stufe 1’s Output als Stufe 2’s Input verwenden, fügen Sie ihn als zitierten Text ein. Nicht zusammenfassen.
- Nie über 4 Stufen ohne Eigentümer-Review hinausgehen. Jede Stufe fügt Drift hinzu; lange ungeprüfte Ketten akkumulieren Fehler.
- Bei der ersten halluzinierten Metrik stoppen. Wenn Stufe 2 einen Spaltennamen erfindet, mit strafferem Schema-Grounding (Element 3) neu starten. Nicht weiter verketten.
Welches Modell für welche Aufgabe
Eine praktische Aufschlüsselung nach Tests über ChatGPT, Claude und Gemini hinweg auf die 12-Prompt-Bibliothek:
| Aufgabe | Bestes Modell | Warum |
|---|---|---|
| Hypothesengenerierung (breit) | ChatGPT | Am aggressivsten beim Produzieren vielfältiger Hypothesen |
| Ehrliche „Ich weiß es nicht”-Antworten | Claude | Am besten kalibriert für Unsicherheit |
| Einhaltung strukturierter Ausgabe | Gemini | Bleibt am besten in JSON-/Tabellen-Formaten |
| Quantitative Analyse (Mathematik) | ChatGPT mit Code Interpreter | Führt tatsächlich Python aus, eliminiert halluzinierte Zahlen |
| Long-Context-Analyse (10K+ Tokens an Daten) | Claude (Opus oder Sonnet) | Beste Kontext-Retention ohne Zusammenfassungs-Drift |
| Schneller Einmal-Prompt | Was Sie offen haben | Ehrlich: Für kurze Prompts sind die Unterschiede minimal |
Der ehrliche Fall, in dem SQL jedes Modell schlägt:
Für spezifische quantitative Fragen („was ist meine Wiederkäufer-Rate?”, „was ist der Umsatz pro Session pro Channel?”) liefert SQL gegen Ihre WooCommerce-Datenbank die korrekte Antwort in Millisekunden. Die KI kann halluzinieren; SQL kann nicht. Verwenden Sie KI für Hypothesengenerierung und Mustererkennung; verwenden Sie SQL für die tatsächliche Mathematik.
Wenn Sie kein SQL schreiben, überbrückt ChatGPTs Code Interpreter (oder Claude mit dem Analyse-Tool) die Lücke – er generiert das SQL aus Ihrem Prompt, führt es auf Ihrem CSV aus und gibt die Antwort mit sichtbarer Berechnung zurück. Das unterscheidet sich vom regulären Chat-Modus, in dem das Modell Zahlen aus dem Kontext rät.
Die Datenschutzgrenze – was sicher einzufügen ist
Statnives Exporte sind bereits datenschutz-sauber:
- Pages-Report – URL-Pfade. Sicher.
- Referrers-Report – source/medium/campaign + Domain. Sicher.
- Geography-Report – Land/Stadt/Region. Sicher.
- Devices-Report – Gerätetyp, Browser, OS. Sicher.
Was vor dem Einfügen entfernt werden sollte:
- Danke-Seiten-URLs –
/order-received/12345/enthält eine eindeutige Bestell-ID. Vor dem Einfügen durch/order-received/[id]/ersetzen, um keine Identifier zwischen KI-Anbietern preiszugeben. - Kundennamen-tragende URLs – Einige Plugins erstellen Benutzerkonto-URLs wie
/my-account/orders/john-smith-2024/. Den Namens-Segment entfernen. - Such-Query-URLs –
?search=customer's-personal-thingkann Intent preisgeben. Entfernen, wenn Sie das nicht in KI-Trainingsdaten haben wollen.
Nichts in Statnives Reports enthält E-Mail-Adressen, IP-Adressen, Zahlungsinformationen oder Lieferadressen. Das Obige sind Sonderfälle für in URL-Pfaden geleakte Identifier, nicht die Hauptberichts-Inhalte.
Warum das „Fragen Sie einfach ChatGPT, was mit meinem Shop nicht stimmt” schlägt
Das häufigste Fehlermuster auf r/WooCommerce und r/ChatGPT sieht so aus:
„Mein Shop konvertiert nicht. Was soll ich tun?”
Das Modell antwortet mit einer 12-Punkte-Listicle generischer E-Commerce-CRO-Ratschläge. Nichts davon ist auf den spezifischen Shop des Betreibers handlungsfähig. Der Betreiber geht weg und denkt, KI sei für CRO nutzlos.
Die 5-Element-Prompt-Anatomie behebt das. Dieselbe Frage, strukturiert:

„Sie sind CRO-Analyst für einen Solo-WooCommerce-Shop mit $20K/Monat. Hier sind meine 30-Tage-Channel-Daten aus Statnives Referrers-Report (cookielos, kein GA4): [CSV]. Statnive trackt noch keinen Umsatz oder Pro-Produkt-Events. Identifizieren Sie die 3 Channels mit dem schlechtesten Bounce/Duration-Verhältnis. Listen Sie für jeden 3 Hypothesen, die die konkreten Zeilendaten referenzieren. Ausgabe als Tabelle. Wenn Sie Daten brauchen, die ich nicht bereitgestellt habe, sagen Sie das explizit.”
Dasselbe Modell, dieselben Daten, dramatisch unterschiedlicher Output. Die Struktur erledigt die Arbeit.
Was v1.0.0 hinzufügt – und was noch auf der Roadmap steht
Mit v1.0.0 (Mai 2026) schaltet der Revenue-Report umsatzbewusste KI-Prompts frei. Die 12-Prompt-Bibliothek integriert bereits Revenue-Report-Daten: Umsatz pro Channel (Prompt 4), Funnel-Drop-off-Diagnose (Prompt 11), Umsatz-pro-Channel-Budgetallokation (Prompt 12).
Noch auf der Roadmap (Growth-Tarif, geplant für 2026):
- Automatisierte wöchentliche KI-Executive-Zusammenfassung. Alle 12 Prompts gegen die Daten Ihres Shops laufen lassen und den konsolidierten Bericht per E-Mail senden – statt dass Sie jeden manuell ausführen. Das ist ein Bezahltarif-Feature; der manuelle Workflow mit Copy-Paste-Prompts bleibt kostenlos.
- Anomalie-getriggerte Prompts. Wenn der Revenue-Report eine signifikante Woche-über-Woche-Abweichung sieht, automatisch den entsprechenden Diagnose-Prompt laufen lassen und den KI-Read innerhalb
/wp-adminanzeigen. Ebenfalls ein geplantes Growth-Tarif-Feature.
Was als Nächstes zu tun ist
- Markieren Sie die 12-Prompt-Bibliothek als Lesezeichen.
- Führen Sie Prompt #1 (Wochen-Review) diesen Montag auf den Overview-Daten Ihres Shops aus.
- Wenn der Output schlecht ist, prüfen Sie, welches der 5 Elemente im Prompt fehlte. Verstärken und neu ausführen.
- Wenn Sie eine neue Analysefrage brauchen, die die Bibliothek nicht abdeckt, verwenden Sie die 5-Element-Anatomie, um Ihren eigenen Prompt zu schreiben.
- Für das vollständige CRO-Betriebssystem siehe den Pillar zu datenschutzfreundlicher Webanalyse für WooCommerce-CRO.
KI für WooCommerce-CRO funktioniert – wenn der Prompt strukturiert ist. Generische Prompts produzieren generische Ratschläge; Statnive-bewusste Prompts produzieren Entscheidungen.